




在当今的医疗领域,随着人工智能(AI)技术的飞速发展,利用大数据进行疾病诊断已成为一种趋势,皮肤病作为常见的健康问题之一,其识别与诊断的智能化进程尤为引人注目,而“皮肤病识别数据集”作为这一进程的核心资源,正逐步成为推动医疗技术创新的关键力量。
一、皮肤病识别数据集的重要性
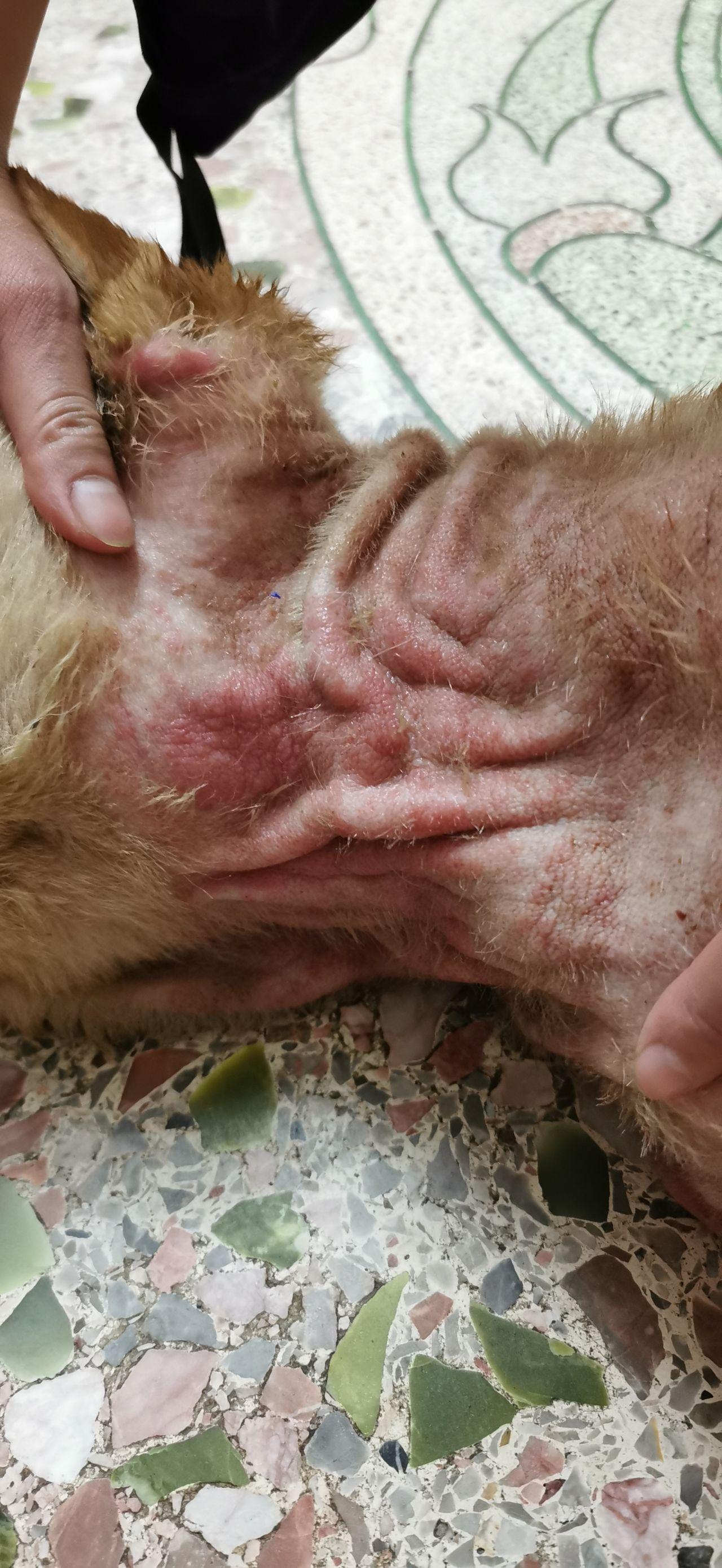
皮肤病,作为影响全球大量人群的疾病之一,其种类繁多、症状各异,从常见的痤疮、湿疹到罕见的皮肤癌等,给患者带来了极大的身心困扰,传统的诊断方式依赖于医生的经验和专业知识,但受限于个体差异、主观判断等因素,往往存在误诊或漏诊的风险,而基于大数据的皮肤病识别技术,则通过分析海量的皮肤图像、病理数据等,能够提供更为客观、准确的诊断结果,极大地提高了诊断的准确性和效率。
二、皮肤病识别数据集的构成与特点
一个高质量的皮肤病识别数据集通常包含以下几个关键部分:
1、图像数据:这是数据集的核心,包括各种皮肤疾病的图像样本,如病变部位的照片、皮肤镜下的图像等,这些图像需经过严格的质量控制,确保清晰度、光线均匀性及病变特征的明显性。
2、元数据:除了图像外,还包括患者的年龄、性别、病史、治疗情况等非图像信息,这些元数据对于模型的训练和优化至关重要,有助于提高模型的泛化能力和诊断的个性化水平。
3、标注信息:每张图像都应附有专业医生的诊断结果和描述,包括疾病名称、严重程度、可能的并发症等,这些标注信息是模型学习的基础,直接关系到识别系统的准确性和可靠性。
4、多模态数据:随着技术的发展,一些数据集还开始整合多模态数据,如皮肤电导率、生物标志物水平等,以提供更全面的诊断依据。
三、皮肤病识别数据集的应用与挑战
应用前景:
辅助诊断:为基层医疗机构和偏远地区提供便捷的远程诊断服务,减少误诊和漏诊。
个性化治疗:根据患者的具体病情和身体状况,提供定制化的治疗方案。
科研与教育:为医学研究提供丰富的样本资源,促进新药研发和治疗方法创新;同时作为教学工具,提升医学生的诊断技能。
面临的挑战:

数据隐私与伦理:在收集和使用患者数据时,必须严格遵守相关法律法规和伦理准则,确保患者隐私不被泄露。
数据质量与多样性:确保数据集的多样性和代表性,避免“标签偏差”和“地域偏见”,提高模型的泛化能力。
技术瓶颈:虽然深度学习在图像识别方面取得了显著进展,但如何进一步提高模型对复杂、微小病变的识别能力仍需突破。
法律与监管:随着AI在医疗领域的广泛应用,如何制定相应的法律法规,确保AI在医疗决策中的角色和责任明确,是一个亟待解决的问题。
四、未来展望
随着技术的不断进步和数据的持续积累,“皮肤病识别数据集”将更加丰富和精准,我们可以期待以下几点发展:

跨学科融合:结合遗传学、免疫学等领域的最新研究成果,构建更加精准的疾病模型。
实时监测与预警:利用可穿戴设备和移动医疗技术,实现皮肤病的早期发现和预警。
无监督学习与自适应性:开发能够自我优化和学习的算法,减少对标注数据的依赖,提高系统的自主性和智能化水平。
公众教育与普及:通过普及皮肤病知识,提高公众对皮肤健康的重视程度,减少因忽视而导致的病情恶化。
“皮肤病识别数据集”不仅是推动医疗AI发展的关键技术之一,更是实现精准医疗、提升人类健康水平的重要工具,在未来的日子里,我们有理由相信,基于大数据的皮肤病智能识别技术将不断突破,为更多患者带来福音。






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...